Sommaire
Bien que l’hébergeur de ma boite mail et de mon site (O2Switch) dispose de son propre filtrage, beaucoup de spams passent au travers de leur protection, et je me retrouve quotidiennement avec une trentaine d’indésirables, j’ai donc isolé manuellement sur ma boite mail Outlook env. 2000 emails indésirables au fil du temps que j’ai placé dans un fichier texte, une adresse mail par ligne.
Pourquoi faire ainsi alors que l’on doit sans aucun doute trouver sur Internet un export texte des noms de domaine (NDD) à filtrer? Parce que chaque boite mail a ses propres spammeurs; Personne ne s’est inscrit en ligne aux mêmes services et ne s’est fait subtiliser son email par les même indélicats.
J’applique un traitement à ces emails; Il consiste essentiellement à supprimer « l’Identifiant » ou « Partie locale » du mail, et à ne garder que le nom de domaine ex: dupont@buzzbizz.net sera réécrit en buzzbizz.net (sans le @). Ainsi non seulement dupont@buzzbizz.net sera reconnu mais aussi tout autre email -comme christine@buzzbizz.net par exemple-. Ceci fait je réimporte le fichier texte ainsi modifié dans Outlook en section « Courrier indésirable ».
Certains emails émanent de sous-domaines; Ex: durand@senior.mutuelledeouf.com, dans ce cas je garde seulement le domaine principal (ici mutuelledeouf.com).
Premier triage avec Notepad++ par odre alphabétique
Dans ce traitement manuel, le problème est que les emails ne sont pas classés par ordre alphabétique…Pourtant cet ordonnancement m’aiderait visuellement.
Pas de problème! Le lecteur Notepad++ propose un triage alphabétique par ligne nommé « Trier par ordre lexicographique », la visualisation du fichier texte est bien plus agréable ainsi, et présente bien souvent des suites de mails similaires commençants par « contact » « infos » « newsletter » que je peux traiter d’un coup grace à Notepad++ et sa fonction de sélection verticale (ALT + Bouton gauche souris puis faire glisser la souris vers le bas: Génial !! ).
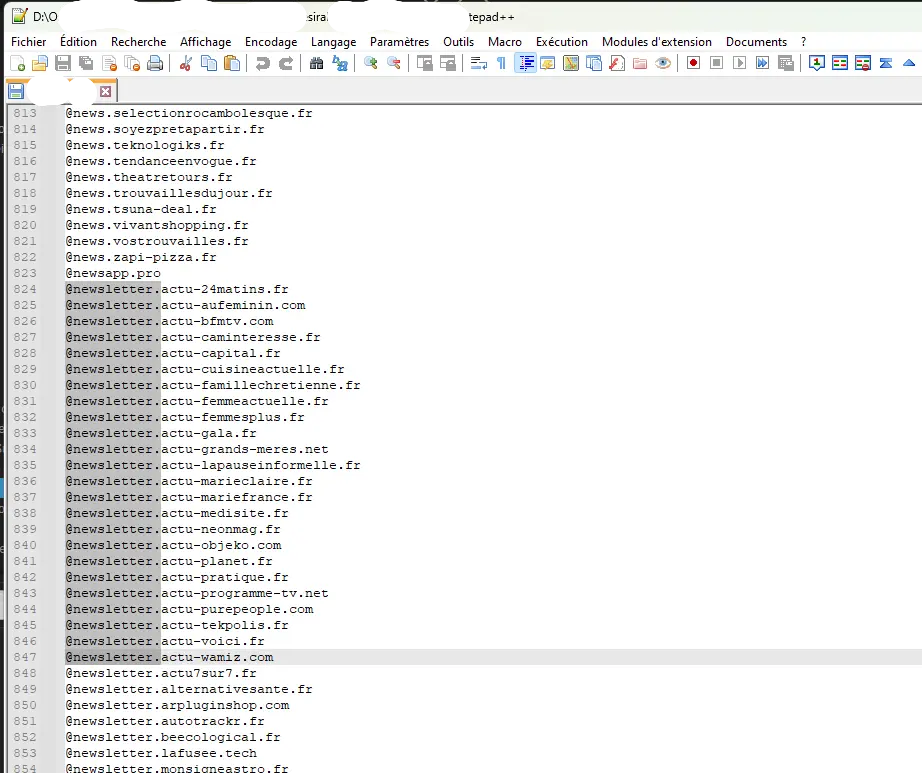
J’ai pensé qu’il devait sûrement exister un moyen de classer de façon plus ergonomique que le trie alphabétique: Le trie par similarité. Bingo! ça existe et ça s’appel le classement Levenshtein. Ci-dessous des extraits de domaines d’emails.
Comparaison visuelle classements alphabétique / Levenshtein
Classement Levenstein
cao.com
co.cz
com.com
eu.com
in.com
net.com
pro.com
ru.com
sale.com
Classement Alphabétique
cao.com
capicloud.best
capital.fr
capturs.com
carenity.com
caresystem1999.com
carlornado.com
carnetvip.com
carnetvip.fr
La comparaison montre que le triage Levenshtein ne se base pas uniquement sur le fait que les suites de caractères comparés contiennent une série de mots semblabes, mais s’appuie aussi sur leurs longueurs.
On ne le voit pas ici dans la capture, mais le triage Levenshtein révèle la répétition d’une suite de mots alors même que cette répétition ne se trouve pas au début des emails; Compétence inconnue en mode trie alphabétique mais cependant très utile pour mon traitement. Ex les email dupond@buzzbizz.net; xantal.dieze@buzzbizz.net, monique@buzzbizz.net seraient contigüs en mode Levenshtein et pas du tout en mode alphabétique.
Cette façon de trier des mots par similarité se rapproche beaucoup plus de la manière humaine de procéder, et cela change tout: J’ai désormais bien plus d’aisance à étudier mon fichier mail.
Script Python sous Windows
Si vos n’avez pas Python: Ce ne sont pas les tutoriels qui manquent, choisissez le votre https://www.google.com/search?q=installer+python+sous+windows.
J’ai préalablement exporté depuis Outlook (version application) les courriels indésirables au format texte sur le Bureau
On ouvre en Administrateur une ligne de commande. Les XXX après Python sont à remplacer par la version de Python installée, version visible en dernière étape d’installation.
cd /d C:\Users\stepm\AppData\Local\Programs\Python\PythonXXX
pip install levenshtein
pip install rapidfuzz
Sous Notepad++ Je renseigne le code Python suivant et l’enregistre sous C:\Users\stepm\AppData\Local\Programs\Python\PythonXXX\Trier_spam_Levenshtein.txt en changeant l’extension txt par py. Je prends la précaution de choisir l’encodage texte UTF-8 dans les options de Notepad++.
from rapidfuzz.distance import Levenshtein
import os
def read_file(file_path):
for enc in ('utf-8', 'latin-1', 'ascii'):
try:
with open(file_path, 'r', encoding=enc) as f:
return [line.strip() for line in f if line.strip()]
except UnicodeDecodeError:
continue
raise UnicodeDecodeError("Impossible de lire le fichier avec les encodages testés.")
def clean_email(email):
return email.partition('@')[0].lower() # Compare juste la partie locale
def group_emails(emails, max_distance=3):
groups = []
ref_keys = []
for email in emails:
key = clean_email(email)
for i, ref in enumerate(ref_keys):
if Levenshtein.distance(key, ref) <= max_distance:
groups[i].append(email)
break
else:
groups.append([email])
ref_keys.append(key)
return groups
def write_file(groups, path):
with open(path, 'w', encoding='utf-8') as f:
for group in sorted(groups, key=lambda g: g[0].lower()):
for email in sorted(group):
f.write(email + '\n')
def main():
input_path = r'C:\Users\MOI\Desktop\indesirables.txt'
output_path = r'C:\Users\MOI\Desktop\indesirables_tries.txt'
emails = read_file(input_path)
groups = group_emails(emails)
write_file(groups, output_path)
print(f"Fichier trié enregistré ici : {output_path}")
if __name__ == '__main__':
main()
Je réouvre une ligne de commande en mode Admin; la commande ci-dessous va lancer l’exécution du script par Python et placer le fichier des emails triés sur le bureau sous le nom « trieLevenshtein.txt ». L’opération peut être longue..
cd /d C:\Users\stepm\AppData\Local\Programs\Python\Python311
python Trier_spam_Levenshtein.py
J’ouvre le fichier de sortie trieLevenshtein.txt. (toujours avec Notepad++). Je cible d’un coup d’oeil les lots d’emails contigües qui contiennent les noms de domaine légitime que je n’inclueraient pas dans mon import futur sous Outlook comme orange.fr, gmail.com, impot.gouv.fr etc… Ce qui n’aurais été moins facile en ordre lexicographique! Concrètement j’efface ces emails du fichier texte. Si je les gardent le traitement Regex suivant va supprimer leurs Identifiants, créant un fichier d’adresses indésirables qui contiendra des noms de domaine d’expéditeurs « honnêtes ».
Je continue le travail sur les emails contenant des occurences d’Identifiants très communs comme newsletter, news, contact.. Pour cette fois isoler leurs noms de domaine en supprimant les Identifiants.
Oui mais.. Il n’en reste pas moins que le travail sur les 2000 lignes restantes s’avère colossal. Notepad++ va s’avérer encore une fois utile.
Regex Notepad++ supprimer la partie avant le @ des Emails
J’accède au menu de Notepad++ puis > Rechercher puis onglet Remplacer. Je coche « Expression régulière ». En champ Recherche je renseigne le Regex suivant:
^.*@.*?([^.]+\.[^.]+)$
- Le caractère ^ indique le début d’une ligne; Couplé avec le signe $ placé en toute fin de cette Regex, cela signifie que le Regex fait un traitement ligne par ligne.
- .* : Reconnait n’importe quelle séquence de caractère littéral quelle que soit sa longueur.
- @ : Littéralement c’est le arobase contenu dans tout mail qui se respecte.
- .*? : Pareil que deux lignes plus haut mais le signe ? impose à ce segment de recherche de s’arrêter à la 1ère occurrence valide (exemple: un simple a, le chiffre 2, etc..) puis de passer la balle au prochain identifieur. Cela évite l’ingestion de noms de domaines, qui doivent être traités par les segments de recherche suivants.
- [^.] : Recherche toute itération du moment que ce n’est pas un point.
- +\. : Cherche un point au sens littéral (d’où l’échappement du . par un antislash).
- [^.]+ : Même principe que deux puces plus haut, sauf que cette partie du Regex ne cherchera pas à la fin de la suite de caractère un quelconque point.
- ([^.]+\.[^.]+) : L’ensemble de cette partie du Regex sera « capturé » pour créer un groupe. Concrètement cette méthode permet de supprimer, remplacer ou garder chaque groupe grace à la fonction Remplacer en lots de Notepad++.
- $ : Le Regex doit trouver un saut de ligne.
❗Avant de cliquer dans Notepad++ sur « Remplacer tout » je fais une copie du fichier.
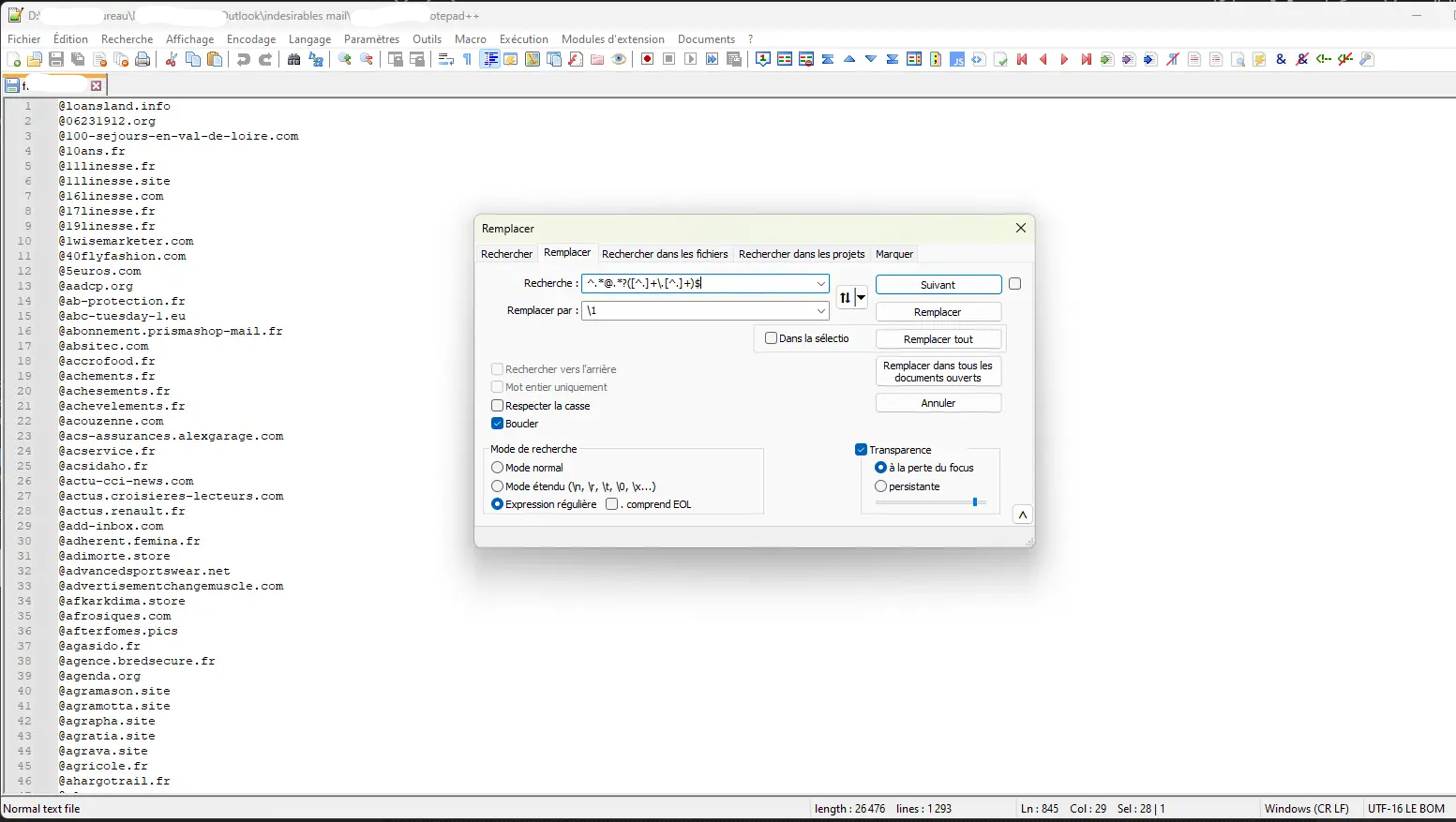
En Regex, chaque groupe capturé en parenthèses est taggé par un numéro d’ordre croissant, ici il n’y a qu’un seul jeu de parenthèse donc ce groupe est désigné par le chiffre 1.
Si on met dans le champs « Remplacer par » de Notepad++ le signe \1 cela signifie que chaque email sera remplacé par le contenu de ce groupe. Imaginons l’adresse email dupont.lignage@pro.business.com:
- dupont.lignage@ correspond bien à ce que recherche la partie du regex .*@ c-a-d toute suite de caractère finissant par un @
- pro. correspond à .*? c-a-d toute suite de caractères, mais le signe ? dit que -si la correspondance est trouvée- ici la lettre p, la suite du traitement doit être passée au segment de recherche suivant seulement si cette prochaine recherche est vérifiée; Explications: dupont.lignage@p est valide, mais la suite « ro.business.com » ne correspond pas à la forme cherchée par ([^.]+\.[^.]+)$ . le process Regex continu alors sa recherche et intégre « r ». Mais « .o.business.com » ne ressemble toujours pas à ce que veut ([^.]+\.[^.]+)$ . Elle persiste en intégrant le o de pro, laissant au reste du Regex la séquence « .business.com » qui n’est toujours pas une séquence valide pour ([^.]+\.[^.]+)$ (ce dernier ne réagit qu’à une suite de caractères Sans points, suivie d’un point puis d’une autre séquence de chiffres et/ou lettres sans points, suivie d’un saut de ligne) . La recherche de correspondance continue; Le point de « pro. » est intégré, laissant au reste la séquence « business.com ». Bingo! la validation de ([^.]+\.[^.]+)$ est faite! La portion Regex « .*? » donne le bâton du relais à ([^.]+\.[^.]+)$ sans continuer davantage d’avaler de données qui risqueraient d’être les fameux noms de domaine que je souhaite isoler dans le groupe Regex n°1.
Regex Notepad++ supprimer les ocurrences réfractaires
Je constate un problème; pour les @ mails comportants un sous-domaine et dont le top-level domain (TLD) est lui-même composé, comme .co.uk. ce script fonctionnera partiellement, par exemple dupont@pro.business.co.uk sera transformé en business.co.uk. Mais ce type d’adresse est rare et sera traité plus loin semi-automatiquement.
Après avoir appuyé sur « Remplacer tout », il faut traiter les courriels (ou plutot maintenant les portions de courriel avec seulement le NDD) dont le TLD est composé. Pour se faire et vu le faible nombre d’entrées correspondantes, une simple recherche Notepad++ suffira.
Voilà le Regex a renseigner dans l’ongle « Rechercher ».
^[A-Za-z0-9]+\.[A-Za-z]{2,3}\.[A-Za-z]{2}$
Le code semble encore plus sybillin que la formule d’extraction précédente, mais elle est en vérité plus simple à comprendre:
- Signe ^ pour indiquer le début de ligne, en couplage avec le signe $ en fin de formule qui lui marque la fin de ligne, ainsi le traitement se fera ligne par ligne.
- [A-Za-z0-9]+\. : Toute suite de chiffres et/ou lettres suivis d’un point dactylographique.
- [A-Za-z0-9]{2,3}\. : Une suite de chiffres et/ou lettres limités à un nombre de 2 ou 3 cherchant le second level domain (SLD).
- [A-Za-z]{2}$ : Deux ou trois lettres. Se termine par un saut de ligne (cherche le TLD).
Mon fichier est importé dans Outlook en section « Expéditeurs bloqués ». J’ai probablement fait quelques erreurs sur un fichier aussi long et me tiens prêt à vérifier ponctuellement le dossier Spams. Et selon la fréquence d’apparition de nouvelles adresses indésirables, je trancherais entre éditer directement sous Outlook ou relancer le script Python.
